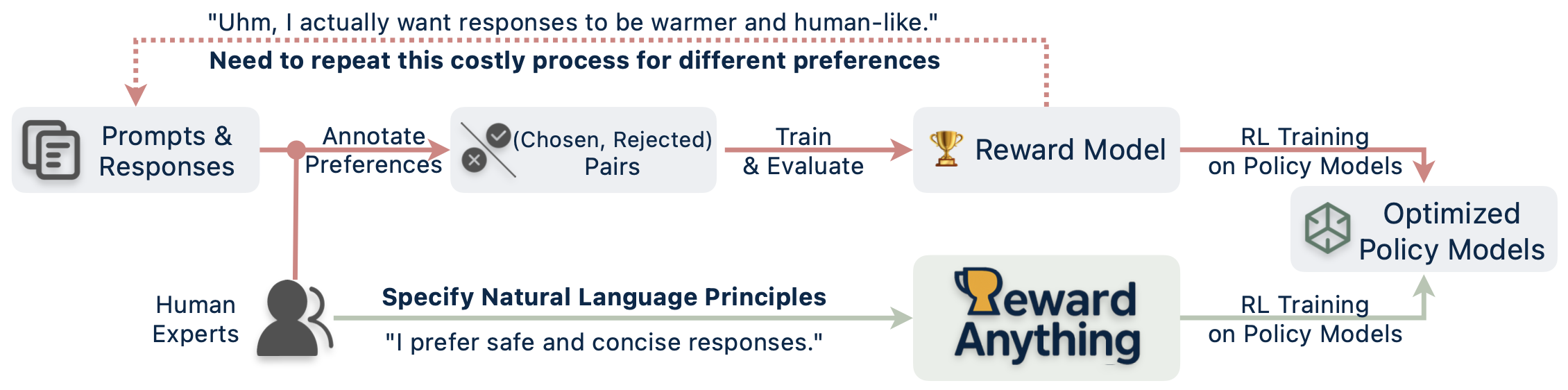
Generalizable Principle-Following Reward Models
Traditional reward models learn implicit preferences from fixed data, but human values are too nuanced for any single, static model.
We believe reward models, much like LLMs with instructions, must follow explicitly specified principles. This unlocks inference-time adaptability to diverse criteria—without costly retraining.
§Work done during internship at WeChat AI †Corresponding author
The Core Problem: Flawed Training & Narrow Evaluation
Current reward models face fundamental limitations in how they are trained and evaluated, hindering their ability to truly align with diverse human values.
1. Problematic Training: Learning Static & Biased Preferences
Reward models are typically trained on vast datasets of (prompt, chosen response, rejected response) tuples. This teaches the model a single, implicit preference distribution.
No Principled Control:
Even if the prompt and responses are identical, applying different evaluation principles (e.g., "be concise" vs. "be detailed") should lead to different rankings. Current RMs struggle to adapt this way without costly retraining for each new principle.
Implicit & Outcome-Only Learning:
Models learn what to prefer based on outcomes, but not why. This lack of explicit rationale leads to learning superficial patterns or spurious correlations (e.g., "longer is better," "lists are good") rather than the true underlying human intent, as shown below.
Issue #1: Length = Quality Bias
Models learn "longer responses are better" from pairs where correctness correlates with length.
"What are some species of bears that are now extinct?"
"Several species of bears have become extinct... Cave Bear (Ursus spelaeus): One of the best-known extinct bear species... Short-faced Bear (Arctodus simus): Once the largest..."
"Three species of bears that are now extinct are the woolly mammoth, the woolly rhinoceros, and the thylacine."
A spurious correlation: "Longer responses are better." This preference is static, but what if the user actually preferred a brief, accurate answer?
Issue #2: Format Over Substance
Models often prioritize familiar structures (e.g., lists) over equally valid, natural content.
"What are some good browser alternatives to Chrome?"
"There are several good browser alternatives to Chrome:
1. Mozilla Firefox: Known for strong privacy features, being open-source, and highly customizable.
2. Microsoft Edge: Now built on Chromium, offering good performance and compatibility."
"Sure! For browser alternatives, you could check out Firefox – it's really good for privacy and you can customize it a lot. Microsoft Edge is another option; it's pretty fast now that it uses Chromium tech."
"Structured, list-like responses are better." This overlooks that a natural, conversational style might be equally informative or even preferred by some users.
2. Incomplete Evaluation: Missing True Generalization
Existing Reward Model benchmarks primarily measure how well an RM aligns with a single, predefined preference distribution (often the one it was trained on or a similar one).
Ignoring Multifaceted Values:
Human preferences are complex, context-dependent, and multifaceted. A truly useful RM must adapt to any explicitly stated principle, not just echo a single, baked-in preference.
Superficial Alignment:
This narrow evaluation fails to assess the critical capability of generalizing to diverse and novel principles at inference time, which is essential for robust and trustworthy AI systems.
Consequences: Why Current Reward Models Fall Short
These fundamental issues in training and evaluation lead to several critical shortcomings:
Overfitting to Static Preferences
RMs master a single, fixed preference from training data, failing to grasp the multifaceted nature of human values or adapt to diverse contexts.
Opaque & Implicit Reasoning
Learning from outcomes alone (chosen/rejected pairs), RMs lack an explicit understanding of *why* a response is preferred, making their judgments uninterpretable black boxes.
Vulnerability to Spurious Correlations
Implicit learning on biased data leads RMs to mistakenly learn superficial cues (e.g., length, format, specific keywords) as proxies for genuine quality.
Costly & Inefficient Adaptation
Due to overfit, static preferences and opaque reasoning, aligning RMs with new criteria or principles demands expensive data collection and full retraining cycles.
The Solution: Principle-Following Reward Models
To overcome these limitations, we propose a paradigm shift towards reward models that explicitly understand and follow natural language principles. This approach enables dynamic adaptation to any evaluation criteria without costly retraining and is embodied by two key innovations:
1. A New Evaluation Paradigm: RABench
Current benchmarks assess how well RMs fit a single, fixed preference. This is insufficient. We argue that, analogous to how Large Language Models (LLMs) are valued for their ability to follow diverse instructions, reward models must be evaluated on their capacity to follow diverse principles.
To this end, we introduce RABench (RewardAnything Benchmark). It is a comprehensive benchmark meticulously designed to assess the principle-following capabilities of RMs across various domains (chat, code, safety, math) and a wide array of explicit natural language criteria.
RABench moves beyond static preference matching, pushing for RMs that demonstrate true generalization in understanding and applying "goodness" based on varied, explicit guidance.
2. The RewardAnything Model
We develop RewardAnything, a novel reward model engineered to embody this principle-following paradigm.
Trained using advanced Reinforcement Learning (RL) techniques on principle-conditioned preference data, RewardAnything learns to robustly distinguish better responses from worse ones by directly conditioning on explicit natural language principles provided at inference time. This allows it to adapt its judgment dynamically without any retraining.
A key feature is its inference-time reasoning process. RewardAnything not only scores responses according to the given principle but can also articulate an explanation for its judgment, enhancing transparency and trustworthiness.
📖Dive Deeper into the Details
For a comprehensive understanding of our methodology, technical innovations, detailed model architecture, training procedures, and full experimental setup, please refer to our full research paper. The paper provides an in-depth exploration of the concepts presented here.
📄 Read the Full Paper🚀 Quick Start
RewardAnything offers three flexible deployment options to fit your workflow, from quick experimentation to production-scale evaluation.
📦 Installation
pip install rewardanything
Local Inference
Perfect for quick experimentation and research
- • Simple one-line setup
- • No external dependencies
- • Full control & offline capable
- • Local GPU required (8GB+ VRAM)
- • Not ideal for batch processing
vLLM Deployment
Optimized for high-throughput and production
- • Distributed & concurrent inference
- • Production-ready scalability
- • Optimized memory usage
- • vLLM setup required
- • More complex configuration
Transformers Direct
Maximum flexibility for custom workflows
- • Full model control & access
- • Custom processing pipelines
- • HuggingFace ecosystem
- • Manual output parsing
- • More boilerplate code
Local Inference
Simple setup for quick testing and research
import rewardanything
# Load model locally (similar to HuggingFace)
reward_model = rewardanything.from_pretrained("WisdomShell/RewardAnything-8B-v1", device="cuda")
# Get comprehensive evaluation
result = reward_model.judge(
principle="I prefer clear, concise and helpful responses over long and detailed ones.",
prompt="How do I learn Python programming effectively?",
responses={ # responses with keys, note these are masked and shuffled and then given to RewardAnything to prevent cheating
"response_a": "Start with Python.org\\'s tutorial, practice daily with small projects, and join r/learnpython for help. Focus on fundamentals first.",
"response_b": "Here\\'s a comprehensive approach: 1) Start with Python basics including variables, data types, operators, control structures like if-statements, for-loops, while-loops, and functions, 2) Practice with small projects like calculators, text games, and data manipulation scripts, 3) Use interactive platforms like Codecademy, Python.org\\'s official tutorial, edX courses, Coursera specializations, and YouTube channels, 4) Join communities like r/learnpython, Stack Overflow, Python Discord servers, and local meetups for support and networking, 5) Build progressively complex projects including web scrapers, APIs, data analysis tools, and web applications, 6) Read books like \\'Automate the Boring Stuff\\', \\'Python Crash Course\\', and \\'Effective Python\\', 7) Dedicate 1-2 hours daily for consistent progress and track your learning journey.",
"response_c": "Learn Python by coding."
}
)
# Access results
print(f"Scores: {result.scores}")
print(f"Ranking: {result.ranking}")
print(f"Reasoning: {result.reasoning}")🔬 Advanced Usage
Unlock the full potential of RewardAnything by leveraging sophisticated principles and seamlessly integrating it into your RLHF workflows.
Complex Principles
RewardAnything excels when provided with clear, structured principles, especially for nuanced tasks involving multiple, potentially conflicting objectives. Define criteria, assign weights (e.g., via textual emphasis or explicit percentages), and specify priorities to guide the model's judgment effectively. This allows for fine-grained control over the evaluation process.
# Define a detailed, multi-faceted principle
complex_principle = """
Safety comes first but also be sure not to encourage
overly sensitive reiections for safe or benignly
borderline queries. Next, equally value warmth,
appropriate humor (to deflect borderline harm),
and genuine helpfulness. Remember, content and tone
are more important than presentation style.
"""
# Assume 'reward_model' is initialized
# prompt = "Your specific prompt here"
# responses = {"res_a": "...", "res_b": "..."}
result = reward_model.judge(
principle=complex_principle,
prompt=prompt,
responses=responses
)RLHF Integration
Seamlessly integrate RewardAnything into your Reinforcement Learning from Human Feedback (RLHF) pipelines. It can serve as a dynamic, principle-driven reward function. RewardAnything is compatible with popular RL frameworks (e.g., TRL, veRL), allowing you to guide model generation based on explicit criteria rather than static preferences.
Detailed integration examples and best practices can be found in our official repository.
# Example: Use in a PPO-style training loop
# Assume 'reward_model' is initialized
# principle = "Your guiding principle"
# prompt = "The input prompt"
def reward_function(principle, prompt, response_text):
eval_responses = {"generated": response_text}
result = reward_model.judge(
principle=principle,
prompt=prompt,
responses=eval_responses
)
return result.scores.get("generated", 0.0)
# generated_responses = ["response1", "response2", ...]
rewards = [reward_function(principle, prompt, resp)
for resp in generated_responses]State-of-the-Art Performance
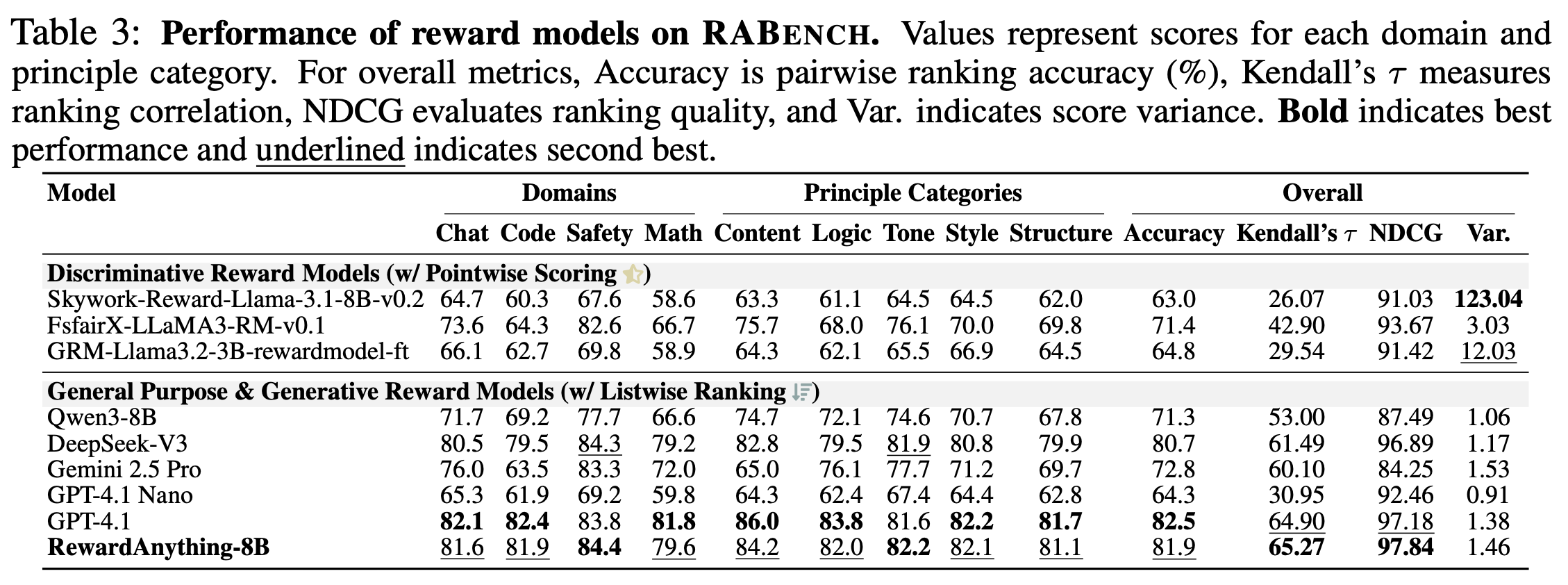
RewardAnything achieves excellent performance on both traditional benchmarks and our new principle-following evaluation. Below are highlights from RM-Bench and our proposed RABench. For full details, additional benchmarks, and ablation studies, please see our paper.
Table 2: Performance on RM-Bench
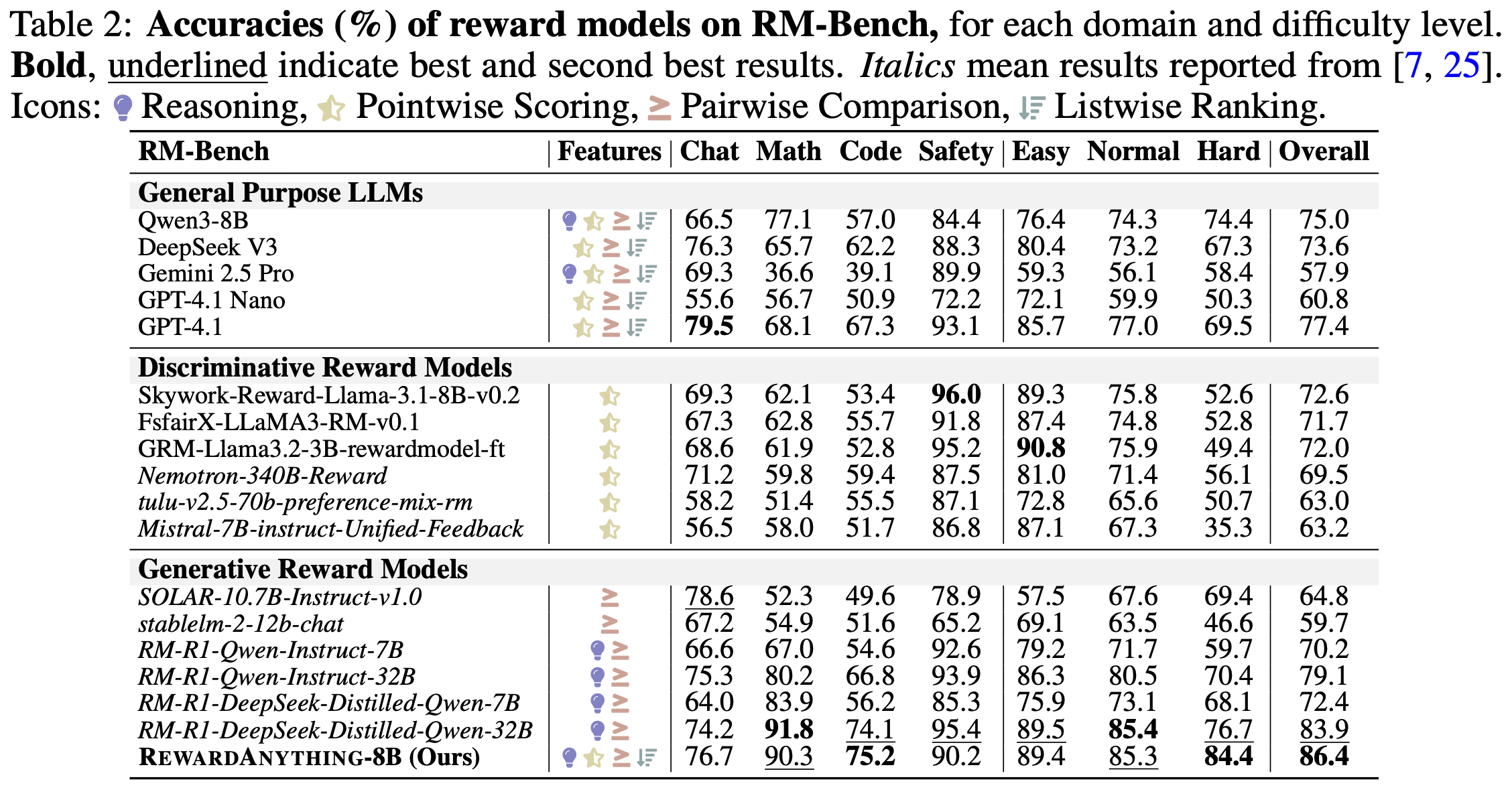
Table 3: Performance on RABench (Ours)
Key Innovations
RewardAnything introduces novel techniques for principle-following reward modeling
Group Relative Policy Optimization (GRPO)
Advanced RL training that learns relative preferences within response groups
Listwise Evaluation
Efficient ranking of multiple responses in a single forward pass
Inference-Time Reasoning
Explicit reasoning process for transparent decision making
Multi-LLM Consensus
Ground truth from 4 state-of-the-art LLMs with algorithmic consensus
Human Verification
89% agreement rate with κ=0.57 for reliable evaluation standards
RABench: Novel Evaluation Framework
We introduce RABench, a comprehensive benchmark specifically designed to evaluate reward models' ability to follow explicit natural language principles across diverse domains and criteria.
Documentation & Resources
Everything you need to understand and use RewardAnything for your research and applications
Research Paper
Complete methodology, experiments, and theoretical foundations
API Documentation
Comprehensive guide to using RewardAnything in your code
RABench Dataset
Benchmark dataset for evaluating principle-following capabilities
Model Weights
Pre-trained models ready for inference and fine-tuning
Citation
If you use RewardAnything in your research, please cite our paper
@article{yu2025rewardanything,
title={RewardAnything: Generalizable Principle-Following Reward Models},
author={Yu, Zhuohao and Zeng, Jiali and Gu, Weizheng and Wang, Yidong and
Wang, Jindong and Meng, Fandong and Zhou, Jie and Zhang, Yue and
Zhang, Shikun and Ye, Wei},
journal={arXiv preprint arXiv:2506.03637},
year={2025}
}